戞4復丂嫟捠尨場屘忈夝愅偺庤朄
丂杮復偱偼嬶懱揑側嫟捠尨場屘忈庢傝埖偄偺偨傔偺丄悢妛儌僨儖偵偍偗傞庢傝埖偄偵偮偄偰婰弎偟丄暅悢偁傞庤朄偺摿怓偵偮偄偰弎傋傞丅
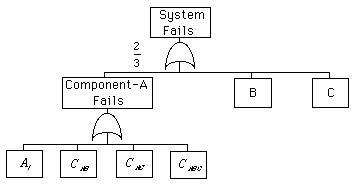
椺偲偟偰丄2-out-of-3僔僗僥儉傪峫偊傞丅
偙偺 3 婡婍僔僗僥儉偵婡婍 A偵偮偄偰娭傢傞CCBE(Common Cause Basic Event)偺姰慡側僙僢僩偲偼丄埲壓偵偁偘傞傕偺偱偁傞丗
傕偟忋婰 CCBE 偺偄偢傟偐偑婲偙傞側傜偽丄婡婍 A 偼屘忈偡傞丅
偙偺昞尰偺幚嵺偺僼僅乕儖僩僣儕乕忋偱偺昞尰偼丄恾 4.1偱帵偡丅婡婍A偺僩乕僞儖偺屘忈偺僽儕乕傾儞娭悢偵傛傞昞尰偼丄
丂![]() 丂丂(4.1)
丂丂(4.1)
僼僅乕儖僩僣儕乕偺悢検壔偼丄僔僗僥儉偺僽乕儕傾儞昞尰傪丄婎帠徾偺妋棪傪敽偭偰偄傞戙悢偺傕偺傊偺曄姺傪梫媮偡傞傕偺偱偁傞丅奺庬偺僼僅乕儖僩僣儕乕僐乕僪偑掕検壔傪慻崬傒偱帩偮傛偆偵側偭偰丄偙偺僗僥僢僾偼傎偲傫偳偺儐乕僓偵偲偭偰丄儐乕僥儕僥傿乕傪巊梡偡傞偙偲偱堄幆偟側偔偰傕傛偄夁掱偵側偭偰偄傞丅
僔僗僥儉屘忈妋棪偑梌偊傜傟傞偲丗
丂![]() 丂丂(4.2)
丂丂(4.2)
偙偙偱
椶帡偟偨婡婍偺椶帡偟偨帠徾偺妋棪偑摨偠
偱偁傞偲壖掕偡傞偙偲偼丄儕僗僋昡壙偲怣棅惈夝愅偱偼捠忢梡偄傜傟傞峫偊曽偱偁傞丅偙偺傾僾儘乕僠偼丄忕挿側婡婍偲摨條丄暔棟揑側懳徧娭學傕棙梡偟偰丄悢検壔偝傟傞昁梫偑偁傞僷儔儊僞偺悢傪尭傜偡偙偲偑偱偒傞丅椺偊偽丄忋婰偺敪惗妋棪傪奺乆嬒堦壔偟偨偲壖掕偡傞偲
![]() 丂(4.3)
丂(4.3)
尵偄姺偊傟偽丄梌偊傜傟偨嫟捠梫場婡婍僌儖乕僾偺斖埻撪偺偄偐側傞婎帠徾偺敪惗妋棪傕丄偦偺婎帠徾偵偍偄偰丄摿掕偺婡婍偱側偔丄悢偺傒偵埶懚偡傞偲傒側偝傟傞丅懳徧惈偵傛傞壖掕偵傛偭偰偺傒摫偐傟偨昞婰朄傪梡偄偰丄僔僗僥儉偺屘忈妋棪傪彂偔偲丄
![]() 丂丂丂(4.4)
丂丂丂(4.4)
偙偙偱僇僢僩僙僢僩忣曬偼幐傢傟偰偄傞丅偟偐偟掕検壔偼傛傝梕堈偵側傞丅
師偵丄m屄偺婡婍偱峔惉偝傟偰偄傞僔僗僥儉傪峫偊偰傒傞丅奺婡婍偼摨條偺庬椶偺婡婍偱奺乆偺撈棫屘忈妋棪偼偳傟傕![]() 偱偁傞偲壖掕偡傞丅偙偺僔僗僥儉偵偍偄偰摿掕偺k屄偺婡婍偑摨帪偵屘忈偡傞妋棪傪
偱偁傞偲壖掕偡傞丅偙偺僔僗僥儉偵偍偄偰摿掕偺k屄偺婡婍偑摨帪偵屘忈偡傞妋棪傪![]() 偲偡傞偲丄摿掕偺1偮偺婡婍偺慡屘忈棪
偲偡傞偲丄摿掕偺1偮偺婡婍偺慡屘忈棪![]() 偼
偼
![]() 乮4.5乯
乮4.5乯
偲昞偡偙偲偑偱偒傞丅偙傟傜![]() 偺
偺![]() 偵懳偡傞斾傪悇掕偡傞曽朄偲偟偰庬乆偺採埬偑側偝傟偰偄傞丅埲壓偵偍偄偰庡梫側曽朄偺奣棯愢柧傪峴偆丅
偵懳偡傞斾傪悇掕偡傞曽朄偲偟偰庬乆偺採埬偑側偝傟偰偄傞丅埲壓偵偍偄偰庡梫側曽朄偺奣棯愢柧傪峴偆丅
偙偺曽朄偼崅壏僈僗楩乮HTGR乯偺PSA夝愅偺嵺偵Fleming偵傛傝採彞偝傟巊梡偝傟偨曽朄偱丄偦偺屻偺嫟捠尨場屘忈夝愅偵偍偄偰峀偔梡偄傜傟偰偄傞丅
偙偺儌僨儖偱偼丄婡婍偺慡屘忈棪傪撈棫屘忈偲嫟捠尨場屘忈偺晹暘偺榓偲峫偊傞丅嫟捠尨場屘忈偑敪惗偡傞帪偼屘忈尨場偑嶌梡偟偨婡婍偡傋偰偑摨帪偵屘忈偡傞偲壖掕偟偰偄傞丅偦傟備偊(4.5乯幃偵偍偄偰![]() 丄
丄![]() 埲奜偼偡傋偰0偲偟丄
埲奜偼偡傋偰0偲偟丄
![]() 乮4.6乯
乮4.6乯
![]() 乮4.7乯
乮4.7乯
![]() 乮4.8乯
乮4.8乯
偺娭學偱僷儔儊乕僞兝傪掕媊偟丄嫟捠尨場屘忈偐傜偺婑梌傪昞尰偡傞丅
丂屘忈棪偺堎側傞擇偮偺婡婍A丄B偺娫偱偺嫟捠尨場屘忈偵傛傞兝僼傽僋僞乕偺庢傝埖偄偼堦斒壔偟偰師偺傛偆偵掕媊偝傟傞丅
![]() 乮4.9乯
乮4.9乯
偙偙偱![]() 偼嫟捠尨場屘忈敪惗棪偱兝僼傽僋僞乕偼偦傟偧傟
偼嫟捠尨場屘忈敪惗棪偱兝僼傽僋僞乕偼偦傟偧傟![]() 丄
丄![]() 偲婡婍偵傛傝堎側偭偨抣偑掕媊偝傟傞丅
偲婡婍偵傛傝堎側偭偨抣偑掕媊偝傟傞丅
NUREG/CR-1150*18偱偼丄暋悢偺婡婍偵懳偟偰傕兝傪奼挘偟偰揔梡偟偰偍傝丄宱尡揑側幃偲偟偰丄僶僢僥儕乕偵懳偟偰
偲偄偆幃傪梡偄偰偄傞丅
4.2.2丂MGL (Multiple Greek Letter)
忕挿搙偑傛傝崅偄僔僗僥儉偺夝愜偵揔梡偡傞偨傔偵丄兝僼傽僋僞乕朄傪奼挘偟偨儌僨儖偱偁傞丅摨偠偔丄m屄偺婡婍偺忕挿宯偵偮偄偰乮4.5乯幃傪傕偲偵峫偊偰傒傞丅
偺幃偵傛傝奺![]() 偑掕媊偝傟偰偄傞丅
偑掕媊偝傟偰偄傞丅
忋幃傪 k= 1,2,3 偵偮偄偰嬶懱揑偵彂偔偲丄
偙偙偱兝丄兞丄兟偵偼師偺堄枴偑偁傞丅
![]() 偼2屄埲忋偺婡婍偺摨帪屘忈敪惗妋棪偱偁傝丄
偼2屄埲忋偺婡婍偺摨帪屘忈敪惗妋棪偱偁傝丄![]() 偼偦偺偆偪偱2屄偩偗偺婡婍偑摨帪偵屘忈偡傞妋棪偱偁傞丅
偼偦偺偆偪偱2屄偩偗偺婡婍偑摨帪偵屘忈偡傞妋棪偱偁傞丅![]() 偼摿掕偺2屄偺婡婍偑屘忈偡傞妋棪偺偨傔慻崌偣偺悢
偼摿掕偺2屄偺婡婍偑屘忈偡傞妋棪偺偨傔慻崌偣偺悢![]() 偱妱傝嶼偟偰偍偔丅
偱妱傝嶼偟偰偍偔丅![]() 偵偮偄偰傕摨條偺娭學偲側偭偰偄傞丅
偵偮偄偰傕摨條偺娭學偲側偭偰偄傞丅
偙偺幃偱兞埲忋偺學悢偑偡傋偰1.0偱偁傞偲偡傞偲丆
偲側傝丄兝僼傽僋僞乕朄偵堦抳偡傞丅
4.2.3丂BFR (Binominal Failure Rate)
偙偺儌僨儖偵偍偄偰偼丄屘忈尨場偲偟偰抳柦揑乮Lethal)側傕偺偲旕抳柦揑乮Nonlethal)側傕偺傪峫偊偰偄傞丅偦傟偧傟偺弌尰昿搙傪冎偲兝偱昞偟丄Lethal Shock偑梌偊傜傟偨帪偼偡傋偰偺婡婍偑妋棪1.0偱屘忈偡傞偲偟丄Nonlethal Shock偺応崌偼奺乆偺婡婍偑妋棪p偱屳偄偵撈棫偵屘忈偡傞偲偟偰偄傞丅
![]() 偲忋婰僷儔儊乕僞偺娭學偼丄
偲忋婰僷儔儊乕僞偺娭學偼丄
偲側傞丅偙偙偱丄偼奺婡婍偺儔儞僟儉屘忈妋棪傪昞偡丅
兝僼傽僋僞乕朄偁傞偄偼MGL儌僨儖偱偼僨乕僞偐傜僷儔儊乕僞抣傪惓妋偵悇掕偡傞偙偲偑擄偟偄丅偦偙偱丄傛傝娙曋側儌僨儖偲偟偰兛僼傽僋僞乕朄偑偁傞丅
兝僼傽僋僞乕朄丄MGL偲傕婡婍屘忈棪傪婎慴偵偟偰偄傞偑丄兛僼傽僋僞乕朄偱偼僔僗僥儉偺屘忈棪傪婎弨偵偟偰偄傞丅偦傟備偊丄兛僼傽僋僞乕朄偺曽偑傛傝捈愙揑偵娤應僨乕僞偲寢傃偮偗傜傟傞偲偄傢傟偰偄傞丅
偙偙偱丄梡偄傜傟傞僷儔儊乕僞偲偟偰丄
![]() 偼丄慡偰偺撈棫帠徾偲嫟捠梫場帠徾偐傜側傞丄奺乆偺婡婍偺僩乕僞儖偺屘忈昿搙丄
偼丄慡偰偺撈棫帠徾偲嫟捠梫場帠徾偐傜側傞丄奺乆偺婡婍偺僩乕僞儖偺屘忈昿搙丄![]() 偼丄擟堄偺k屄偺婡婍偑嫟捠尨場偵傛傝屘忈偺敪惗偡傞妱崌偲掕媊偝傟偰偄傞丅
偼丄擟堄偺k屄偺婡婍偑嫟捠尨場偵傛傝屘忈偺敪惗偡傞妱崌偲掕媊偝傟偰偄傞丅
偲側傝丄丄偲偺娫偵偼埲壓偺娭學偑惉棫偡傞丅
![]() 偼婡婍偺慡屘忈憤悢偵斾椺偟丄
偼婡婍偺慡屘忈憤悢偵斾椺偟丄![]() 偼擟堄偺k屄偺婡婍偑摨帪偵屘忈偡傞応崌偺婡婍屘忈悢偵斾椺偡傞丅
偼擟堄偺k屄偺婡婍偑摨帪偵屘忈偡傞応崌偺婡婍屘忈悢偵斾椺偡傞丅![]() 偼摿掕偺1屄偺婡婍偑懠偺擟堄偺k-1屄偲摨帪偵屘忈偡傞妋棪偲側偭偰偄傞丅偦傟備偊丄摿掕偺k屄偺婡婍偑摨帪偵屘忈偡傞妋棪
偼摿掕偺1屄偺婡婍偑懠偺擟堄偺k-1屄偲摨帪偵屘忈偡傞妋棪偲側偭偰偄傞丅偦傟備偊丄摿掕偺k屄偺婡婍偑摨帪偵屘忈偡傞妋棪![]() 偼丄慻崌偣偺悢
偼丄慻崌偣偺悢![]() 偱妱偭偰乮4.23乯幃偺條偵側傞丅
偱妱偭偰乮4.23乯幃偺條偵側傞丅
偙傟傜偺僷儔儊乕僞乕偺巊梡偼丄僨乕僞儀乕僗偺拞偺僔僗僥儉偺曐廋偺曽朄傗帪婜偵娭偡傞悇掕偵埶懚偡傞丅Staggerd test(忕挿婡婍側偳丄僔僗僥儉偺暋悢偺婡婍偺帋尡帪婜傪偢傜偟偰丄旕怣棅搙偺僺乕僋抣丄暯嬒抣傪壓偘傞帋尡曽朄丅*嶲峫帒椏1嶲徠)偑峴傢傟偨応崌偵偼(2.23)幃偼曄峏偝傟傞丅
* Staggered Testing Scheme
![]() (4.26)
(4.26)
* Nonstaggered Testing Scheme
偙傟偼(4.19)偲摍偟偔丄
![]() (4.27)
(4.27)
偙偙偱
![]() (4.28)
(4.28)
椺偲偟偰丄3婡婍僔僗僥儉偺婎帠徾偺妋棪偼乮staggered僥僗僩傪壖掕偡傞偲乯埲壓偺傛偆偵側傞丗
![]() (4.29)
(4.29)
偟偨偑偭偰丄僔僗僥儉旕怣棅搙偼丄埲壓偺傛偆偵昞傢偣傞丗
![]() (4.30)
(4.30)
Impact Vector偼丄兛僼傽僋僞偺僷儔儊乕僞丄枖偼MGL偺兝丄兞丄兟偺寛掕偵嵺偡傞掕検揑側悇掕偵梡偄傞偙偲偑偱偒傞丅婡婍僌儖乕僾扨埵偱偺屘忈敪惗傪丄儀僋僩儖傪梡偄傞偙偲偱丄偄偔偮偐偺働乕僗偵懳偟敪惗妱崌傪暘晍偝偣傞偙偲偑偱偒傞丅偙傟偼婡婍偺慡屘忈憤悢偐傜慻傒崌傢偣偛偲偵敪惗妱崌傪寛掕偟偰峴偔兛僼傽僋僞朄偲恊榓惈偑崅偄丅
Impact Vector偱偼丄傑偢丄僾儔儞僩偵偍偄偰偺帠徾偺塭嬁偺婰弎傪姰椆偡傞偨傔偵丄暘愅幰偼丄埲壓傪妋擣偡傞昁梫偑偁傞丅
帠徾偺崻杮揑尨場偲楢寢儊僇僯僘儉偵偝傜偝傟偨偲巚傢傟傞乮揟宆揑偵椶帡偟偨乯婡婍偺悢(m)
帠徾拞偱丄塭嬁傪庴偗偨乮椺丗屘忈摍乯婡婍僌儖乕僾偺斖埻撪偺婡婍偺悢
婡婍僌儖乕僾偺斖埻偵娷傑傟傞乮抳柦揑側僔儑僢僋乯埥偄偼娷傑傟側偄乮旕抳柦揑側僔儑僢僋乯偵暘偐傟傞丅慡偰偺婡婍偺屘忈偵偍偄偰丄揟宆揑側寢壥偵偄偨傞偨傔偺尨場偲儊僇僯僘儉偑懚嵼偟偨偐偳偆偐傪昞傢偡丅
摿桳偺婡婍偺婡擻傊偺塭嬁丅乮椺丗僨儅儞僪帪丂奐幐攕乯
丂婡婍偺悢傪戙昞偟丄僒僀僘 m 偺婡婍僌儖乕僾偵偍偄偰婲偙偭偨帠徾偺塭嬁儀僋僩儖偼丄 m+1屄偺梫慺傪帩偭偰偄傞丅傕偟 k 婡婍偑屘忈偡傞帠徾側傜偽丄慡偰偺懠偺梫慺偑 0 偱偁傞娫丄塭嬁儀僋僩儖偺 k斣栚偺梫慺偼1偱偁傞丅塭嬁儀僋僩儖偺僶僀僫儕昞尰偼
![]() (4.31)
(4.31)
偲側傞丅
椺偲偟偰丄2 out of 3 (m=3)偺僔僗僥儉偵偍偄偰婡婍偑嫟桳偝傟偨尨場
(F2 =1丄F3=1)偱屘忈偟偨 帠徾傪峫偊傞偲丗
偙偺塭嬁儀僋僩儖偵奺乆偺敪惗妋棪傪偐偗傞偙偲偵側傞丅偙偺偲偒丄2婡婍偑屘忈偟偨妋偐傜偟偝傪0.9偲偡傞偲
![]() (4.34)
(4.34)
偙偺敪惗偺妋偐傜偟偝偺抣偼丄暘愅幰偺僙儞僗偵傛偭偰偩偗嵏掕偡傞偙偲偑偱偒傞丅偟偐偟側偑傜丄偦偺傛偆側傾僙僗儊儞僩傪梕堈偵偡傞偨傔偵丄偁傞庬偺僈僀僪儔僀儞偼採埬偝傟偰偄傞丅
丂偨偩偟偙傟偼丄帠徾敪惗帪偺屘忈偺娫妘傪PRA巊柦帪娫偵懳偡傞暘椶偑昁梫偱偁傝丄staggered僥僗僩偺桳柍偵偮偄偰傕峫椂偑昁梫偱偁傠偆丅
EPRI NP-3967偱峴傢傟偰偄傞惍棟偵偍偄偰丄偙偺夁掱偑梡偄傜傟偰偄傞恾昞傪恾 4.2偵帵偡丅
帠徾偺曬崘偼丄 恾 4.2a 偲 4.2b 偺拞偺椺偑堄枴偡傞傎偳偼柧妋偱偼側偄丅傎偲傫偳偺応崌丄帠徾偺婰弎帺懱偑娙扨偱偼側偄丅婡婍偺惓妋側忬懺偑丄偄偮傕抦傜傟偰偄傞偲偄偆栿偱傕側偄丅偦偟偰崻杮揑尨場偼傔偭偨偵恎尦偑抦傜傟偰偄側偄傕偺偱偁傞丅帠徾偺堎側傞夝庍傪戙昞偟偰丄偦傟備偊偵帠徾 偺夝庍乮 恾s 4.2a 偲 4.2b 偺椺偺傛偆側宍幃傊偺帠徾婰弎偺東栿乯偑丄奺乆偄偔偮偐偺壖愢傪嶌偭偰偟傑偆偺傪昁梫偲偡傞偐傕偟傟側偄丅
椺偲偟偰恾 4.3a 偱暘椶偝傟偨帠徾傪峫偊傛偆丅幚嵺偵俁斣栚偺僨傿乕僛儖婡娭偑幐攕偟偰傕偄偨偐偳偆偐妋怣偑側偄応崌丄僶僀僫儕塭嬁儀僋僩儖偼丄 2 偮偺堎側傞壖愢乮 恾 4.3b 乯偺壓偱昡壙偝傟傞丅嵟弶偺壖愢偺壓偱偼丄2 僨傿乕僛儖婡娭偩偗偑峫椂偝傟傞丅偟偐偟丄俀斣栚偺壖愢偱偼丄俁偮偺慡偰偺僨傿乕僛儖婡娭偼屘忈偟偰偄偨偙偲偵偡傞丅偙偺揰偱暘愅幰偼丄 2 偮偺壖愢偺奺乆偵懳偡傞怣棅搙傪偼偭偒傝偝偣傞偨傔丄偁傞掱搙丄嵏掕偡傞昁梫偑偁傞丅恾 4.3b 偺椺偱偼丄幚嵺偵偼 2偮偺僨傿乕僛儖婡娭偩偗偑屘忈偟偰偄偨偲偄偆敾抐偵偍偗傞帺怣偺旕忢偵崅偄搙崌偄傪傪斀塮偟偰丄0.9 偺僂僃僀僩偑丄嵟弶偺壖愢偵梌偊傜傟傞丅戞俀偺壖愢偨傔偺僂僃僀僩偼憤榓偑侾偵側傞偨傔偵柧傜偐偵 0.1 偱偁傞丅僂僃僀僩梫場偺僾儘僷僥傿偱慡偰偺崌棟揑側壖愢偑愢柧偝傟傞偙偲偵側傞丅僨乕僞暘愅幰偼偙偺昡壙傪慡偰柧帵偟丄暥彂壔偟側偗傟偽側傜側偄丅
2 偮偺壖愢傪偲傝丄塭嬁儀僋僩儖偵傛傞曄姺塭嬁儀僋僩儖偺梊憐抣偑丄埲壓偵偁偘傞傕偺偱偁傞丅
恾 4.3b 偱傕帵偝傟傞丅Fi 偑扨弮側僶僀僫儕塭嬁儀僋僩儖偵尵媦偟丄Pi偼暯嬒偺塭嬁儀僋僩儖偵尵媦偡傞丅